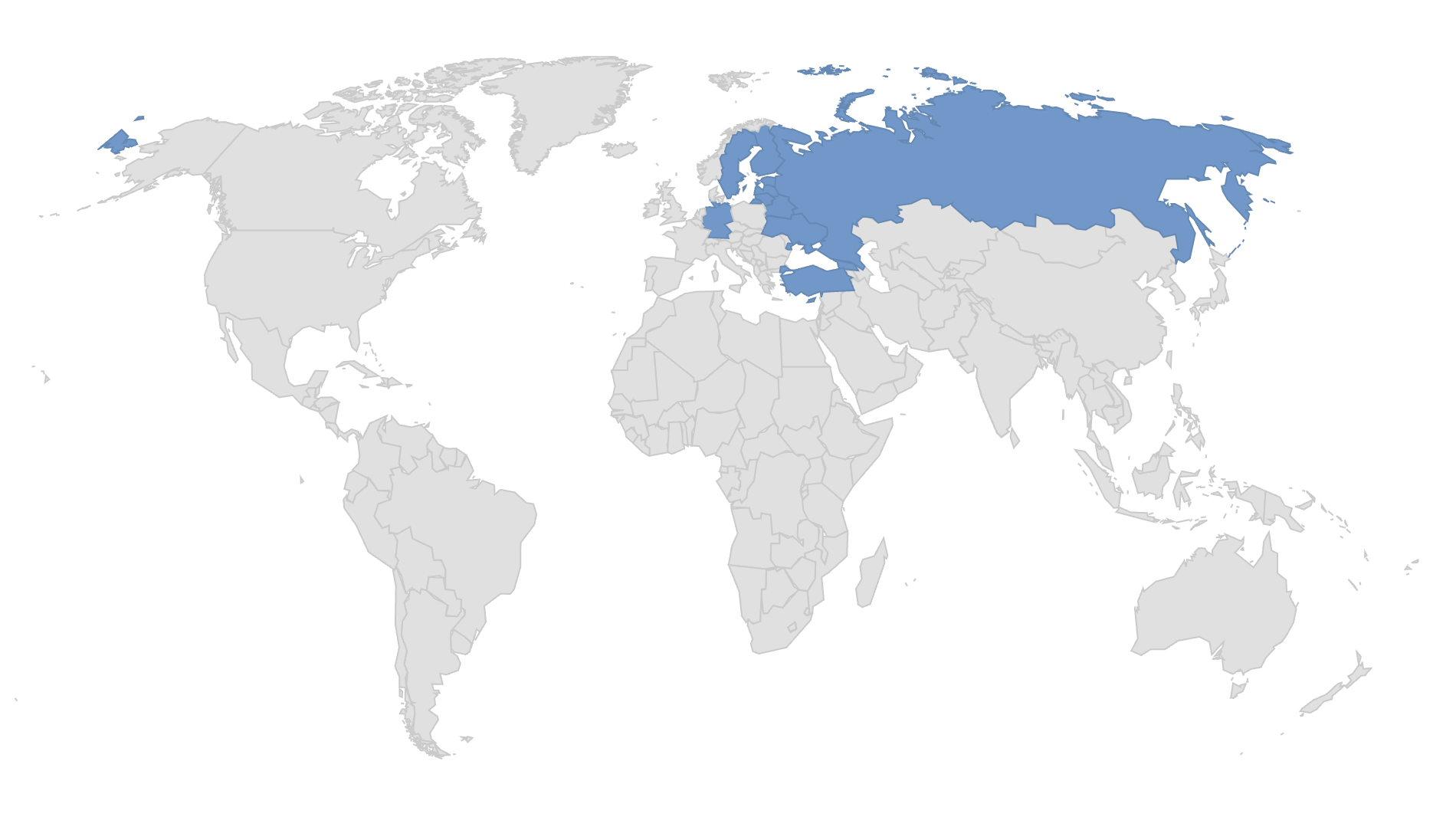
5%, надо больше
Я зачем-то подписан в телеге на вакансии яндекса, листаю и вижу «декодируйте SW52YWxpZCBjaGFyYWN0ZXIgaW4gaW5wdXQgc3RyZWFtLgo=», ну думаю это же base64, всё просто, декодирую и вижу результат «Invalid character in input stream.\n», хм, наверное тут просто какая-то своя таблица сопоставлений символов с кодами, наверное есть какой-то алгоритм SW52, например, короче заинтересовался… потом подумал что тут просто кириллический символ в исходной строк, проверяю, нет, везде латиница. Ну значит нужно разбираться что за кодер тут такой. А потом понял, что я тупица. Такая вот история
На вашей даче вы используете 4g-модем для выхода в интернет, кроме этого вы решили организовать там небольшую локальную сеть с видеонаблюдением и какой-нибудь автоматизацией, конечно же вы используете raspberry pi для этих целей. Но вот беда: ваш провайдер прячет вас за NAT, бесполезно открывать и переадресовывать порты на роутере, вы не сможете попасть в сеть. Я применил проброс портов, это очень распространенное решение, приведу пример как я это сделал (имея дома белый статический IP). Уточним инфраструктуру: на каждой стороне есть роутер с выходом в интернет, а внутри сети есть какой-нибудь сервер, в моем случае это машинки rasbperry pi, они и будут держать связь между собой.
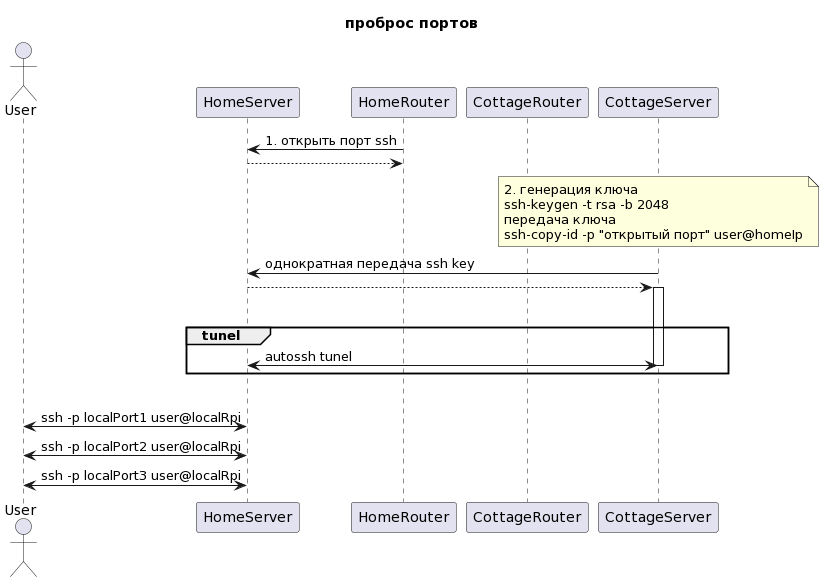
ssh-keygen -t rsa -b 2048
ssh-copy-id -p "порт открытый на шаге 1" user@homeIpssh -R XXXX:localhost:22 -p XXXX user@homeIp[Unit]
Description=AutoSSH tunnel service on local port 22
After=network.target[Service]
User=your_user_name
Environment="AUTOSSH_GATETIME=0"
ExecStart=/usr/bin/autossh -M 20000 -o "ServerAliveInterval 30" -o "ServerAliveCountMax 3" -N -R XXX:localhost:22 -i /home/user/.ssh/your_file -p XXX user@homeIp[Install]
WantedBy=multi-user.targetsudo systemctl daemon-reloadsudo systemctl start autossh.tunel.servicesudo systemctl enable autossh.tunel.serviceПоговорим о параметрах autossh, один из них M, означает monitoring, если установить его в 0, то мониторинг соединения будет выключен, можно будет увидеть сообщение в логах port set to 0, monitoring disabled, в теории такие туннели будут тухнуть молча. Статья объясняет этот параметр и пока я пробую мониторить некоторые порты, а некоторые нет, чтобы на практике почувствовать разницу поведения программы. Ещё нужно будет добавить параметр T, который вроде бы не будет создавать фантомный терминал создавая туннель (не должно быть видно в команде who).
Нельзя полагаться на часы в распределенных системах, потому что, даже при условии синхронизации их по NTP, они не будут полностью синхронны и разница будет расти со временем. Тем не менее, если такая система обменивается сообщениями, то встает вопрос в необходимости определения последовательности событий между хостами. Предположим, что хост генерирует события и некоторые из них (или все) отправляет по сети в виде сообщений, принимающая сторона фиксирует (обрабатывает) у себя эти сообщения аналогично тем, что уже обработала сама ранее (внутренние или внешние). Если мы станем рассматривать эти сообщения в порядке их появления, то мы отсортируем их по времени, но время у каждого хоста свое. Попробуйте запросить выборку событий в период времени у каждого хоста и вы удивитесь результатам, так как некоторые хосты будут считать что событие А уже наступило в этот период времени, а другой хост будет считать иначе. Таким образом, если мы сделаем выборку событий за период времени с каждого хоста, то из-за различий во времени, мы получим неоднозначность, например, события-источники могут иметь отметку времени более позднюю чем события-приемники. Я пытался найти для себя удачный пример, нашел его в лекции ИТМО “Введение в распределенные вычисления”, они предлагают нам представить банковские филиалы которые обмениваются денежными переводами. Каждый филиал в случайные промежутки времени производит транзакцию перевода денежных средств в другой филиал (дебит), внутри себя или принимает внешний перевод (кредит). Требуется посчитать сумму средств во всех филиалах за период времени. В условиях рассинхрона времени может оказаться что средства отправленные из филиала A будут отмечены временем T1, при этом филиал-приемник B зарегистрирует транзакцию во время T2, но если время в филиале B отставало от времени в филиале A, то окажется, что транзакция пришла раньше чем ушла (по мнению B), что само по себе абсурдно и может вообще не попасть во временные рамки периода. Это означает, что сумма денежных средств в банках не будет равна ожидаемой, первоначальной сумме. Часы Лемпорта могут нам в решении этой задачи, суть состоит в том, что событие имеет ID, оно отправляется в FIFO канал другого хоста, тот принимает его и обрабатываем следующим образом:
Таким образом, мы имеем систему в который физическое время не учитывается, а все транзакции могут быть отсортированы по времени наступления. Я написал простой пример-реализацию, в нем проверяется, что при слиянии всех транзакций от всех хостов, транзакции списания (исходящие) происходили раньше чем транзакции пополнения (входящие).
Если бы нам повезло жить в мире, где все изменения и коммуникации происходят мгновенно, то жизнь в IT упростилась бы, но в фактически, иногда, происходят ошибки, уточнения, исправления которые необходимо фиксировать в реестрах и базах данных. Проблема в том, что не всегда возможно переписывать историю заключенную в виде строк в БД, к тому же это может быть небезопасно с точки зрения приложения. Иногда это практически невозможно, например, в случае с блокчейном. Есть замечательная статья об этом, в которой нас подводят к этой проблеме через пример: некая Салли получает повышение зарплаты и письмо от HR приходит с опозданием, платежная ведомость уже была сформирована на «старую» сумму, когда фактически должна была быть уже на «новую». Проблема усугубляется тем, что в письме содержалась ошибка и через несколько дней приходит новое, уточняющее письмо с уточненной суммой. В итоге получается что нам нужно дважды переписывать историю, причем мы просто потеряем эту информацию спустя время, ведь об инциденте не останется следа. Решение сводится к тому, чтобы сохранять информацию о фактическом времени наступления события и о времени записи.
Оказывается что это не просто сухая теория, существует компания marklogic которая создала коммерческую документоориентированную СУБД и продвигает эту концепцию, вот их описание проблемы https://www.marklogic.com/blog/bitemporal/, а вот более краткая презентация. Есть и opensource вариант — https://opencrux.com/main/index.html, вообще после описания идеи temporal databases в стандарте SQL:2011 многие СУБД начали реализовывать эту фичу у себя.
В итоге: эта идея заключается в сохранении информации не только о фактах (как в традиционных БД), но и о наших знаниях об этих фактах в определенный момент времени.
Иммутабельность необходима для избежания «глупых» ошибок в программах, которые, думаю, всегда связаны со случайным изменением передаваемого объекта в потоке выполнения программы. Часто бывает, что при работе с датами, деньгами, координатами в пространстве и подобными вещами удобно создать класс-представление содержащий набор значений и использовать его как тип данных. Вот к нему и стоит предъявить требование неизменяемости. Хотя, во время реализации этого требования, может прийти мысль об избыточности. Я сейчас говорю о избыточности при выделении памяти во время конструирования копии объекта. Есть шаблоны проектирования, в которых обеспечивать неизменяемость уже стало хорошим тоном, например, М. Фаулер предписывает делать Value Objects иммутабельными всегда и приводит в своих статьях примеры вида: имеется базовая дата в виде VO, присваиваем её переменной, рассчитывая работать с этой датой (вызовем метод add) и… базовая дата изменилась! Вся магия произошла в момент присваивания даты переменной — это один и тот же объект. Обычно этого, не происходит в функциональных языках, а в ОО языках, скорее всего, произойдет. Есть статья об этой проблеме в которой описано как именно технически реализовать иммутабельность.
Выше я говорил про паттерн Value object, но есть ведь похожий паттерн Data Transfer Object, нужно ли в нём стараться обеспечивать неизменяемость? Почему вообще встал этот вопрос? Ведь многие скажут что эти шаблоны проектирования — одно и тоже. На сколько я знаю, это разные шаблоны, хоть и похожи но отличаются они тем, что DTO служит для коммуникации между процессами или передачи данных из метода в метод. То есть как преимущество мы получаем меньшее количество параметров (множество переменных упаковывается в объект), некоторую типизацию, возможность сериализации параметров, но не нужно рассматривать его как неделимый тип данных (он не является датой, суммой, координатами …), а ещё не стоит добавлять туда никакую логику. А вот VO наоборот, является «неделимым», целостным типом данных, например сумма денег вместе с валютой или координаты, при этом сюда можно добавить метод сравнения типов между собой или что-то подобное. Но это не железное правило, потому что объект типа Request, содержащий данные запроса от клиента к серверу, я бы отнес к DTO и при этом сделал бы неизменяемым. Я бы не хотел чтобы запрос клиента (Request) в процессе работы моей программы как-то изменился, это может внести ошибки.
DDD (Domain-Driving Design) — это концепция разработки ПО которая основывается на сущностях из предметной области разрабатываемого приложения. Эрик Эванс написал об этом книгу «Предметно-ориентированное проектирование» из которой мы узнали, что разработчику следует оперировать терминами из предметной области, следует понимать их, я бы добавил к этому что при материализации их в коде, стоит «затерминейтить» их — сделать отдельный неймспейс сущности которого не будут ссылаться ни на что. Но, они могут ссылаться (зависеть) друг на друга и, более того, bounded context как раз об этом. Сами модели доменов действуют как UbiquitousLanguage (вездесущий язык) для коммуникации между специалистами в предметной области и разработчиками.
Домены — базовые сущности, значение которых должно быть однозначным, это очень важно при создании ПО. В реальных организациях, кстати, это часто не так и многие термины внутри одной большой организации могут пониматься по-разному в разных отделах. В мире компьютеров это недопустимо. Можно построить тотальную схему моделей всего бизнеса с уникальными сущностями? Ответ: это очень сложно и дорого. Ведь если под термином X в одном отделе понимается нечто, а в другом отделе понимается что-то похожее, но с существенными различиями, то сложно будет зафиксировать единое определение доменной сущности удовлетворяющее всех. Проще оставить разделение по отделам внутри каждого из которых будет своя модель доменов, да и продумать все модели с учетом будущего развития — задача сложная и бизнес не готов отдать столько времени на проектирование.
Итак, связанный контекст позволяет на высоком уровне смапить взаимоотношения сущностей между крупными логическими блоками приложения, в которых домены с одинаковыми названиями будут иметь свои, локальные, особенности и черты. Это позволяет нам не собирать единую гигантскую систему доменов, а оставить слабовязанные «микросервисы» жить отдельно.
Мартин Фаулер в мае 2019 года опубликовал статью Zhamak Dehghani, а затем, свою статью, в которой ссылаясь на оригинал описал свои мысли по поводу оригинальной статьи. Автор описывает подход к работе с озером данных — data mesh. Тут надо рассказать о моём понимании происходящего: если вы записываете данные в подготовленном виде, например, в таблицы своей СУБД, то есть вы трансформируете их перед записью, то вы используете хранилища данных, если вы складываете сырые данные как есть, например логи веб-серверов, на сервера amazon s3, без какой-либо трансформации (ведь вы не знаете что именно из этих данных вам понадобится), кроме вас это делают и другие команды компании, то можно говорить что вы используете озеро данных. Можно сказать что мы определяем схему данных при чтении работая с озером данных и при записи работая с хранилищем данных. Под схемой данных понимается то, что за данные мы хотим получить, откуда, какой объём, когда нам это нужно… Существует опасность накопить неактуальные, ненужные данные в озере, за этим нужно следить, но как преимущество мы получим возможность спускаясь на любую глубину озера получать нужные нам данные заранее не зная (при записи) что нам понадобится.
Автор начинает с описания видов данных (data planes): операционные и аналитические, где первые используются приложениями, а вторые аналитиками. Данные перетекают через ETL в аналитические хранилища которые тоже делятся на хранилища данных и на озера данных, с этого я начал. Статья не о том, какова разница между двумя этими технологическими стеками, а о том, что data mesh может быть применён к обоим подходам. Цель data mesh — создать почву для извлечения данных в любых масштабах. Для достижения этой цели предлагается 4 принципа:
Я думаю что внедрение этих принципов поможет бороться с недостатками озера данных, такими как неконтролируемое накопление ненужных данных или отсутствие стандартизации. Рамки принципов помогут аналитикам быстрее понимать данные в озере.
Данные имеют владельца который должен следить за актуальностью, исторической целостностью и быть ответственным за них. Для большего погружения автор отправляет нас изучать этот раздел. Кроме операционной составляющей данных, это принцип требует предоставлять возможность изучать данные аналитически, например, предоставить API. Таким образом экосистема поддерживающая этот принцип позволяет легко масштабировать количество источников данных, количество сценариев использования, имеет разнообразные модели доступа.
Одна из проблем аналитики данных — разобраться со скоплением данных, ведь те, кто эти данные накапливают могут по-разному понимать цели и по-своему представлять зачем это нужно. Поэтому в обязанности data owner’а входит: понимание для кого эти данные собираются, кто их потребители и каким способом они хотели бы их получать. Все data products должны иметь стандартизированные интерфейсы. Каждый домен включает в себя роль data product developer отвечающую за распространение и обслуживание данных. Data product это узел data mesh содержащий 3 структурных компонента:
Включает в себя код пайплайнов для перегонки данных из операционного хранилища, API для доступа и принудительные проверки возможности доступа к данным.
В зависимости от природы данных это графики, таблицы, файлы — в общем сами исходные данные. Метаданные нужны для удобства их ассоциирования с источниками, тут могут быть ссылки на документацию, схемы данных.
Позволяет нам собирать, распространять и запускать весь наш data product.
Прошлая парадигма, когда пайплайны для работы с данными существовали «сами по себе», работали со всеми данными и управлялись отдельно, противопоставляется data mesh когда все компоненты (код, данные и инфра) рассматриваются как единое целое. Эта мысль напомнила мне о том, что совсем недавно появилась профессия DevOps и работа команд изменилась таким образом что сейчас команда сама разрабатывает, деплоит код и обеспечивает инфраструктуру. Можно вспомнить как было раньше, когда разработчики отдавали код в отдел администрирования который по документации сам производить миграции, деплоил код и мониторил продукт, в этом случае команды как бы противостояли друг против друга.
В итоге, пользователи data products могут легко исследовать данные, понимать их, данные распределены среди множества доменов.
Существует множество аспектов при разработке ПО в IT: сборка, подготовка, распространение, мониторинг, управление доступом … и data product добавляется сюда же. Поэтому, чтобы не добавлять сложностей, важно иметь возможность управления данными на высоком уровне абстракции, этот принцип называется Self-serve data infrastructure as a platform to enable domain autonomy, наверное это можно перевести как самообслуживающаяся инфраструктура данных как платформа должна позволять доменам быть автономными. Вообще говоря, все эти принципы, они не про то, что нужно взять и поставить определенные программы и как-то их настроить, а про то, к чему мы должны стремится в построении data mesh. Автор упоминает историю о том, что, например, разработчики деплоят через докер и оркестрируют через кубер, а есть там же аналитики которые используют spart job и всех этих ребят надо «поженить», так вот этот принцип про то, что это должно быть реализовано.
Поговорим о том, что self-serve платформа может обслуживаться разными способами
Domain teams могут создавать и потреблять данные автономно, используя абстракции платформы, прячущей сложности сборки и выполнения.
Data mesh следует распределенной архитектуре: набор независимых data products, с независимым жизненным циклом, сборкой, деплоем и независимыми командами. Однако, эта система нуждается в управлении, в существовании единых правил, но федеративно управляемых. Традиционные системы управления достигают своих целей через централизованные решения, причем решения не могут быть подвержены изменениям или неточным толкованиям. Federated governance наоборот поддерживает изменения, эксперименты и различные толкования правил.
В итоге, потребители данных гарантированно получают доступ ко всем доменам поддерживающим единые стандарты и по единым правилам.
Музыка редко когда заходит, мне больше нравится просто шум. Открыл для себя генератор шумов — норм тема.
Мне, почему-то, нравятся рассказы про лагерную жизнь, помню как я понял это читая «Архипелаг Гулаг», давным-давно. Потом у Довлатова были «Записки Надзирателя», у Достоевского «Записки из мертвого дома», их я, правда, не осилил. Дело в том, что вроде интересно, но я удивлен описываемым характерам героев и происходящему: все какие-то слишком добрые там, на зоне, все простые как 3 копейки, я уж не знаю, то ли люди тогда такие все были, в те времена. Преступники все у него простодушные, что даже не верится. Ну попал на каторгу, ну судьба значит такая у меня, буду жить потихоньку, мечтать о свободе, срок мотать…
У Солженицына в Архипелаге зона совсем другая, он пишет о лагерниках и о Сталинском времени, там и война и голод, он разделает зеков по политическим мотивам и воров, делает на этом акцент. В Иване Денисовиче такого разделения не описывается, в целом зек у него совестливый человек: каторжные строят стену, стараются делать ровно, качественно, когда звенит гудок закончить работу, они не уходят все бросив, они заканчивают работу (!) и только потом уходят. В Записках Надзирателя помню сцену где вор, чтобы не работать, отрубает себе, кажется, пальцы. Вот такой контраст.
Так же, автор пишет о тяжёлой судьбе надзирателя, вскользь, но все же упоминает этот момент. Эта идея широко раскрыта у Довлатова.
Автору книги, описав один день жизни зека, удалось описать всю его жизнь.